Google TurboQuant and Entity-Driven SEO: What the Compression Breakthrough Actually Means for Your Site
TurboQuant is a vector quantization algorithm from Google Research that dramatically compresses the mathematical representations AI uses to understand meaning. If it reaches production search infrastructure, it could lower the cost of semantic retrieval at scale — making entity-based content signals more dominant and keyword-match signals relatively less important.
Quick answer
TurboQuant is a Google Research vector compression algorithm that reduces the memory cost of high-dimensional vectors — the building blocks of semantic search and AI answer generation — by up to 8x with minimal accuracy loss. It is not a ranking algorithm and is not confirmed in production Google Search. But if deployed at scale, it could lower the computational barrier to running deeper semantic retrieval, which would benefit content structured around entities, topics, and intent rather than keyword density.
What TurboQuant Actually Is (Not a Ranking Update — a Compression Method)
Published on Google Research's blog in March 2026, TurboQuant is a set of vector quantization algorithms designed to compress high-dimensional vectors — the numerical representations AI models use to encode meaning, context, and relationships — with near-zero accuracy loss. The headline result from Google Research: memory reduction of at least 6x, and up to 8x performance improvement on Nvidia H100 GPUs.
Let's be clear about what it is not. TurboQuant is not a Google Search ranking algorithm. It is not a core update. Google has not confirmed it is in production use within Search. What it is: a compression technique that could make it dramatically cheaper and faster to run vector-based retrieval at the scale Google operates.
Two sub-components underpin the approach. QJL (a 1-bit trick with near-zero overhead) and PolarQuant (which encodes angle-based relationships between vectors rather than raw values). Together, they preserve the geometric structure of vectors even under aggressive compression — which is the critical property for maintaining semantic search quality.
Why Vector Compression Has SEO Implications at All
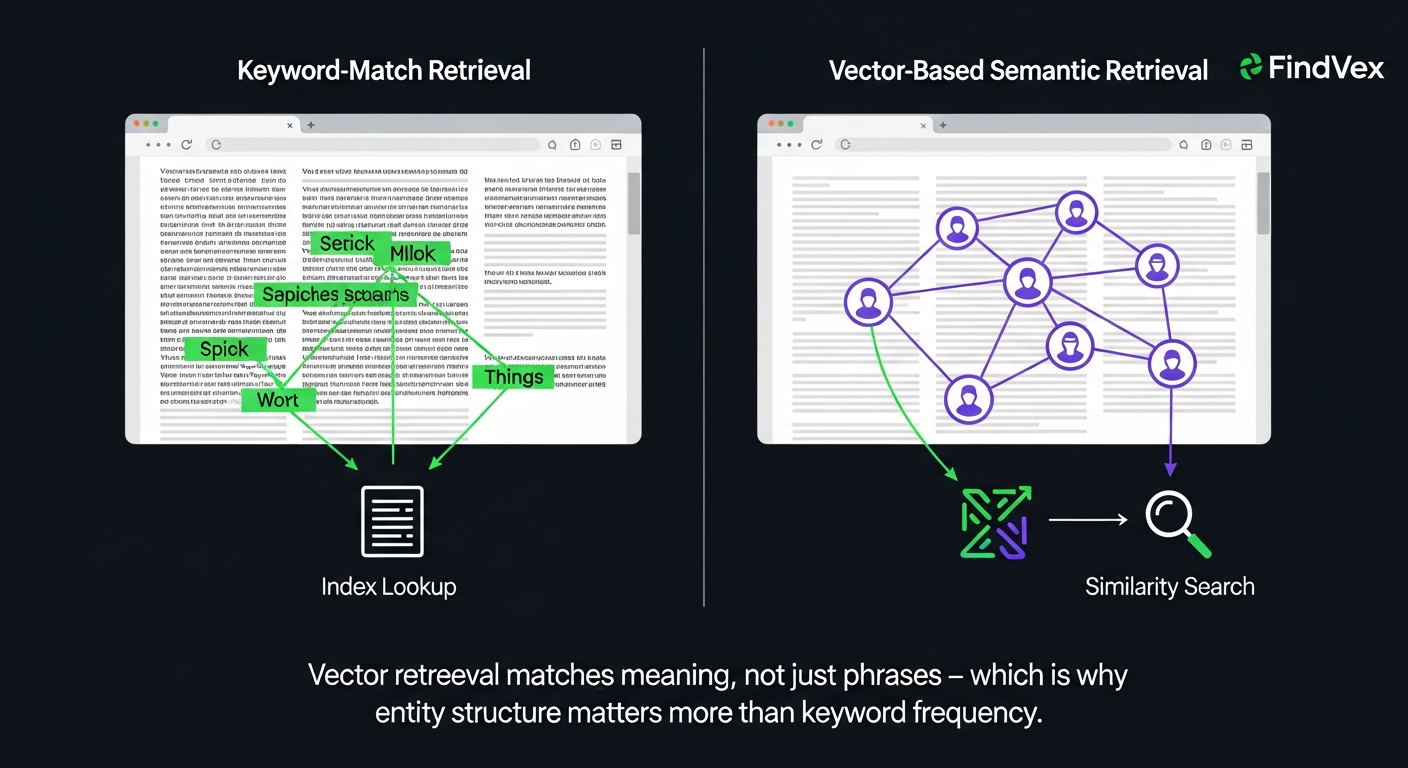
To understand why a compression algorithm could affect how your content ranks, you need to understand what vectors do in Google's systems. When Google processes a page, it doesn't just store keyword counts — it creates dense numerical representations (embeddings) that capture meaning, topic relationships, and intent. These embeddings are what power semantic matching: the reason a page about 'burst pipe emergency' can rank for 'water damage plumber near me' without containing that exact phrase.
The problem has always been cost. High-dimensional vectors are memory-intensive. Running similarity lookups across billions of documents using uncompressed vectors is expensive. That cost creates a practical ceiling on how many candidate documents a system can semantically evaluate before defaulting to faster, cheaper signals — like keyword match.
If TurboQuant reduces the memory footprint of those vectors by 6x to 8x without meaningfully degrading retrieval accuracy, the ceiling rises. Google could run deeper semantic candidate pools at the same infrastructure cost. That has downstream implications for which content surfaces — and the content that benefits is structured around topics, entities, and intent rather than exact-match phrases.
Vector database provider Qdrant has already shipped TurboQuant in version 1.18, describing it as a config change that delivers competitive recall at half the storage cost of its previous scalar quantization approach. That's a real-world signal that the algorithm performs as advertised outside of Google's own research environment.
“AI agents do in hours what teams used to do in weeks. The advantage compounds.”
How This Accelerates the Shift Toward Entity-Driven Content
Search Engine Land's analysis of TurboQuant framed this as a potential acceleration of entity-driven SEO — the model where Google understands your page not as a bag of keywords but as a document about specific entities (people, places, products, concepts) with defined relationships between them.
That framing holds up technically. When semantic retrieval becomes cheaper, the gap between 'keyword-rich but shallow' and 'entity-rich but dense' content closes faster. A page that clearly defines what it's about, who it's for, and how its core concepts relate to each other becomes easier for a vector-based retrieval system to match to the right query — even when the query phrasing differs from the page's exact language.
For AI Overviews specifically, this matters more than for traditional blue-link rankings. AI Overview generation is a retrieval-augmented process: the system pulls candidate passages, evaluates semantic fit, and synthesizes an answer. A cheaper, faster semantic retrieval layer means more candidates can be evaluated, and the selection criteria shift further toward topical authority and entity coverage.
- Entity coverage: Pages that name, define, and contextually link key entities in their topic area become more retrievable.
- Topical depth over keyword density: A page covering one topic thoroughly outperforms one that mentions many keywords shallowly.
- Intent alignment: Content structured to answer the question directly — not to rank for a phrase — fits vector retrieval better.
- Freshness signals: Cheaper vector indexing could lower the latency on fresh content reaching semantic retrieval pools.
- Structured markup as disambiguation: Schema helps AI systems identify entities precisely, reducing ambiguity at retrieval time.

Diagnosis Checklist: Is Your Content Ready for Deeper Semantic Retrieval?
You don't need to wait for TurboQuant to be confirmed in production to audit whether your site is positioned for a more entity-aware retrieval environment. These symptoms indicate your content is built for keyword-match retrieval, not semantic retrieval.
Risk level for each item is noted. Low risk means it's a quick win with minimal disruption. High risk means involving a developer or SEO professional before making changes.
- SYMPTOM: Pages rank for exact-match queries but miss semantically adjacent ones. CAUSE: Content targets phrases, not topics. FIX: Expand each page to cover the topic entity fully — definitions, use cases, related concepts. RISK: Low.
- SYMPTOM: No schema markup on key pages. CAUSE: Entities are unnamed in machine-readable format. FIX: Add LocalBusiness, Article, FAQPage, or Service schema as appropriate. RISK: Low.
- SYMPTOM: AI Overviews for your target queries cite competitors, not you, even though you rank. CAUSE: Your content isn't retrieval-ready — it lacks the clear, self-contained passages that LLM retrieval favors. FIX: Add direct-answer paragraphs in the first 100 words of each section. RISK: Low.
- SYMPTOM: Your internal linking is based on navigation menus, not topic relationships. CAUSE: Google's understanding of your entity graph relies on link architecture. FIX: Link related topic pages to each other with descriptive anchor text. RISK: Low.
- SYMPTOM: Thin pages covering many topics shallowly. CAUSE: Content strategy optimized for keyword count, not topic authority. FIX: Consolidate or expand. One thorough page beats five shallow ones. RISK: Medium — involves content restructuring.
What to Check in Google Search Console
TurboQuant's potential production deployment won't announce itself in Search Console. But you can use GSC right now to identify gaps that a more semantic retrieval environment would expose.
- Performance > Queries: Filter for your top pages and check whether the queries driving impressions are topically related or mostly exact-match variants of your target keyword. If they're almost all exact-match, your page isn't being retrieved for semantically adjacent queries.
- Performance > Pages: Find pages with high impressions but low CTR. These are candidates for direct-answer restructuring — the kind that makes a page more attractive in AI Overviews and featured snippets.
- Index Coverage: Check for 'Crawled — currently not indexed' URLs. If Google is crawling but not indexing pages, thin or low-entity-density content is a likely cause.
- Enhancements: Review whether schema markup is being validated and whether rich result eligibility is confirmed. Unvalidated schema means your entity signals aren't reaching Google's structured data systems.
- Core Web Vitals: Fast-loading pages get crawled more frequently, which means fresh entity updates reach Google's index faster. A slow site is indirectly a freshness problem.
Developer Handoff Notes: What This Means for Technical Implementation
If you're briefing a developer or technical SEO on entity-readiness work, these are the implementation priorities. None of these require waiting on TurboQuant's production status — they're sound technical SEO regardless.
- Schema markup implementation: Add JSON-LD schema for all primary entity types on the site. For local businesses: LocalBusiness with full NAP, hours, service area, and sameAs links to authoritative profiles. For content pages: Article or FAQPage. Risk level: Low. Owner: Developer or SEO plugin configuration.
- Internal link architecture audit: Map which pages link to which, and verify that topically related pages reference each other. Use a crawl tool (Screaming Frog, Sitebulb) to generate the link graph. Risk level: Low. Owner: SEO or content team.
- Passage-level content structure: Ensure each H2 section contains a self-contained answer in the first 1–2 sentences. This is how retrieval-augmented systems extract passages. Risk level: Low. Owner: Content team.
- Canonical hygiene: Confirm canonical tags are correctly set on all pages, especially paginated content, filtered views, and near-duplicate service pages. Duplicate entity signals dilute retrieval precision. Risk level: Medium. Owner: Developer.
- Rendering audit for JavaScript-heavy sites: If key entity content (service descriptions, FAQs, location data) is rendered client-side only, Googlebot may not see it at crawl time. Use Google's URL Inspection tool to compare rendered vs. raw HTML. Risk level: High if misconfigured. Owner: Developer.
What TurboQuant Does Not Mean for Your SEO
The coverage of TurboQuant in SEO circles has generated some overclaiming worth correcting.
TurboQuant is not confirmed in production Google Search. The Google Research blog post describes a research advance, not a Search deployment. The SEO implications are conditional on that deployment happening and affecting the retrieval layer that Google uses for ranking and answer generation.
Keywords are not dead. Vector retrieval systems still rely on initial candidate sets that keyword matching helps define. A more efficient semantic layer amplifies the advantage of topically deep content; it doesn't make keyword relevance irrelevant.
You do not need to rewrite your entire site. The practical response is incremental: audit your schema, deepen your weakest topic pages, strengthen your internal link architecture, and structure content for passage-level retrieval. These are the same good-practice signals that work in the current environment.
Don't let anyone sell you a 'TurboQuant optimization service' that involves anything beyond the entity-readiness work described above. There is no TurboQuant switch to flip in your content or code.
The 3-Step Entity Readiness Audit You Can Run This Week
This isn't about TurboQuant specifically. It's about positioning your site for a retrieval environment that is moving toward semantic matching regardless of whether TurboQuant accelerates it. These three steps are the highest-leverage starting points.
- Step 1 — Schema audit (30 minutes): Run your homepage and top 5 pages through Google's Rich Results Test (search.google.com/test/rich-results). Identify missing or invalid schema. Add or correct LocalBusiness, Service, and FAQPage markup. This is the most direct way to make your entity signals machine-readable.
- Step 2 — Topic coverage audit (1–2 hours): For each of your top 10 pages, ask: does this page fully define the entity it's about? Does it answer the likely follow-up questions? Does it link to related topic pages on your site? If a page feels thin on any of those, expand it. Focus on depth over length — one precise paragraph beats three generic ones.
- Step 3 — Passage structure review (1 hour): Read the first sentence of every H2 section on your key pages. If it doesn't directly answer the implicit question the heading poses, rewrite it. AI retrieval systems pull passages — they're not reading your page top to bottom.
FAQs
Is TurboQuant currently affecting Google Search rankings?
No confirmed production deployment in Google Search has been announced. TurboQuant is a Google Research publication describing a vector compression algorithm. Its SEO implications are conditional on Google deploying it in their search or AI Overview infrastructure. The underlying trend it could accelerate — toward semantic and entity-based retrieval — is already underway regardless.
What is vector quantization and why does it matter for SEO?
Vector quantization compresses high-dimensional numerical representations (vectors) that AI systems use to encode meaning. In search, vectors power semantic matching — the ability to connect a query to a relevant page even when the phrasing differs. More efficient vector compression means semantic retrieval can run at larger scale with lower compute cost, which could shift the advantage toward content with strong entity and topic coverage.
What is entity-driven SEO and how is it different from keyword SEO?
Keyword SEO optimizes for specific phrases appearing on a page. Entity-driven SEO optimizes for the topics, concepts, people, places, and products a page is definitively about — and how those entities relate to each other. Search systems increasingly use entity signals (including schema markup, internal link structure, and topical depth) to understand what a page is about beyond its exact wording.
Should I add schema markup because of TurboQuant?
Schema markup is worth adding regardless of TurboQuant. It makes your entities machine-readable, improves eligibility for rich results, and helps AI Overviews identify your content as a reliable source on a topic. If your key pages are missing LocalBusiness, FAQPage, or Article schema, that's a gap worth closing now.
Does TurboQuant affect AI Overviews directly?
Not confirmed. AI Overview generation involves a retrieval-augmented process where candidate passages are semantically matched to a query. A more efficient vector retrieval layer could theoretically expand the candidate pool AI Overviews evaluate, which would benefit well-structured, entity-rich content. But this remains speculative until Google confirms the deployment.
Who should own entity readiness work — the content team or a developer?
It depends on the task. Schema markup implementation is typically a developer task (or handled via an SEO plugin). Content restructuring for topical depth and passage-level clarity is a content team task. Internal link auditing spans both. For small businesses, the highest-impact and lowest-risk starting point is schema — many WordPress and Shopify plugins handle this without custom code.
Research notes
Background claims used while researching this article. Verify with the cited authorities before quoting.
- TurboQuant delivers at least 6x memory reduction and up to 8x performance improvement on Nvidia H100 GPUs — verify via Google Research blog post — https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/ — published March 24, 2026. Editor should verify exact figures before publication.
- Qdrant shipped TurboQuant in version 1.18 with competitive recall at half the storage cost of scalar quantization — verify via Qdrant technical article — https://qdrant.tech/articles/turboquant-quantization/ — published May 13, 2026. Editor should verify version number and benchmark claims.
- Search Engine Land framed TurboQuant as a potential accelerant of entity-driven SEO — verify via Search Engine Land — https://searchengineland.com/turboquant-entity-seo-477216 — published May 13, 2026. This is the primary source brief references; editor should confirm article framing before publishing.
Marcus Chen
Head of Technical SEO · Findvex
Marcus Chen heads technical SEO at Findvex. He writes about Core Web Vitals, indexing, schema, and JavaScript SEO — translating Google’s documentation into checklists small business owners can actually act on.
Expertise: Core Web Vitals · Indexing & crawlability · Schema / structured data · JavaScript SEO
Related reads
How AI Is Changing Local Search Visibility: What the SOCi + Google Webinar Revealed
Google and SOCi's joint webinar on local search visibility highlighted a fundamental shift: AI-powered discovery across Google Search, Maps, and Gemini now requires a different optimization playbook than the one most small businesses are running. Here's what changed and what to prioritize.
Strategic Technical SEODuplicate Content SEO: What Google Actually Penalizes vs. What It Silently Handles
Duplicate content rarely triggers a manual penalty. Google usually picks one version and ignores the rest. But the wrong choice by Google can split your ranking signals, waste crawl budget, and suppress pages you actually want ranked. Here's how to diagnose the difference.
SEO NewsFrom SEO Expert to AI Search Expert: How to Control What AI Says About Your Brand
Search engine optimization is no longer just about rankings — it's about controlling what AI says when someone asks about your industry, your competitors, or your brand. Here's the strategic shift every SEO and business owner needs to make now.